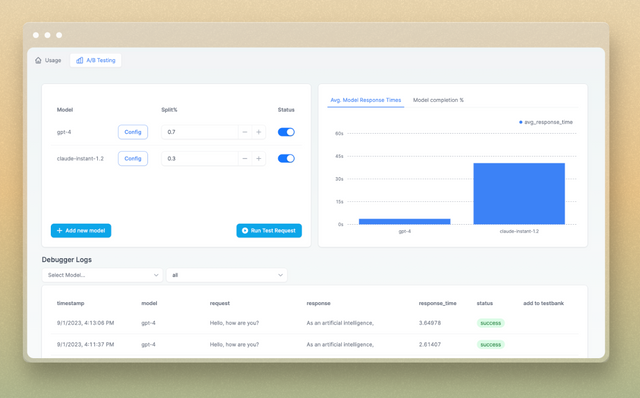
Split traffic betwen GPT-4 and Llama2 in Production!
In this tutorial, we'll walk through A/B testing between GPT-4 and Llama2 in production. We'll assume you've deployed Llama2 on Huggingface Inference Endpoints (but any of TogetherAI, Baseten, Ollama, Petals, Openrouter should work as well).
Relevant Resources:
Code Walkthrough
In production, we don't know if Llama2 is going to provide:
- good results
- quickly
💡 Route 20% traffic to Llama2
If Llama2 returns poor answers / is extremely slow, we want to roll-back this change, and use GPT-4 instead.
Instead of routing 100% of our traffic to Llama2, let's start by routing 20% traffic to it and see how it does.
## route 20% of responses to Llama2
split_per_model = {
"gpt-4": 0.8,
"huggingface/https://my-unique-endpoint.us-east-1.aws.endpoints.huggingface.cloud": 0.2
}
👨💻 Complete Code
a) For Local
If we're testing this in a script - this is what our complete code looks like.
from litellm import completion_with_split_tests
import os
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key"
os.environ["HUGGINGFACE_API_KEY"] = "huggingface key"
## route 20% of responses to Llama2
split_per_model = {
"gpt-4": 0.8,
"huggingface/https://my-unique-endpoint.us-east-1.aws.endpoints.huggingface.cloud": 0.2
}
messages = [{ "content": "Hello, how are you?","role": "user"}]
completion_with_split_tests(
models=split_per_model,
messages=messages,
)
b) For Production
If we're in production, we don't want to keep going to code to change model/test details (prompt, split%, etc.) for our completion function and redeploying changes.
LiteLLM exposes a client dashboard to do this in a UI - and instantly updates our completion function in prod.
Relevant Code
completion_with_split_tests(..., use_client=True, id="my-unique-id")
Complete Code
from litellm import completion_with_split_tests
import os
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key"
os.environ["HUGGINGFACE_API_KEY"] = "huggingface key"
## route 20% of responses to Llama2
split_per_model = {
"gpt-4": 0.8,
"huggingface/https://my-unique-endpoint.us-east-1.aws.endpoints.huggingface.cloud": 0.2
}
messages = [{ "content": "Hello, how are you?","role": "user"}]
completion_with_split_tests(
models=split_per_model,
messages=messages,
use_client=True,
id="my-unique-id" # Auto-create this @ https://admin.litellm.ai/
)
A/B Testing Dashboard after running code - https://admin.litellm.ai/